可以设想一下,当你驾驶着一辆新能源汽车在高速上驰骋,你脚下的数据采集器在一秒钟内通过提前设置的80个指标采集到了80个数据,总大小为2KB,你可以在一分钟的单位时间内观测这些不断回传的数据,运用它们实时分析你想知道的任何状况,但在此之前必须要通过一个靠谱的数据库来对珍贵的数据进行写入、保存。毋庸置疑,时序数据库要接入大量设备的实时数据,加载性能至关重要! 本节你将会利用MatrixDB中的高级组件MatrixGate、MatrixBench进行强大的数据接入性能测试,为之后的数据分析提供靠谱保障。 我们的物理机硬件测试环境如下,硬件环境参数有可能会影响工具配置参数,记得选取适合自己的。
1 硬件环境
机器配置如下:
| 参数 | 配置 |
|---|---|
| CPU核数 | 2物理核 32逻辑核 |
| CPU平台 | Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz |
| 内存 | 256GB |
| 储存容量 | 9.0TB(1.4 GB/秒写入,3.3 GB/秒读取) |
| linux发行版本 | CentOS Linux release 7.8.2003 (Core) |
| linux内核 | 3.10.0-1127.el7.x86_64 |
2 专业工具
2.1 MatrixGate
MatrixGate简称mxgate,是一款高性能流式数据加载服务器,位于MatrixDB安装目录下的bin/mxgate。该工具会充分发挥分布式数据库的并行处理性能,是生产环境中做数据加载的必选工具。在测试环节,mxgate将配合mxbench的数据写入工具writer对随机数据生成器generator生成的数据进行高速写入。
更多相关信息请见mxgate
2.2 MatrixBench
mxbench 是一款数据加载和查询的压测工具,可以根据你想要的设备数量、时间范围、指标数量等配置并快速生成随机数据,自动创建数据表,串行或并发进行数据加载和查询。你可以通过命令行配置并运行mxbench,也完全可以写进特定的配置文件,遵从个人习惯即可。mxbench工具位于MatrixDB安装目录下的bin/mxbench。
3 部署方式
MatrixDB:单机部署,master + 6个segment
注意!
你需要把MatrixGate,MatrixBench与MatrixDB集群部署在同一台机器上。
4 开始测试
4.1 测试用例
我们准备了三种不同指标规模的时序场景测试用例。在此节末尾,我们会对不同指标规模下MatrixDB的写入速度做直观对比。
- 10w设备,10个指标
- 10w设备,100个指标
- 10w设备,1000个指标
4.2 开始测试
注意!
使用mxbench进行加载测试前你需要准备好mxbench的测试环境:包含正常运行的MatrixDB集群,以及配置好的相关环境变量。此步是必要步骤!mxgate无需手动配置,因为在启动mxbench的同时,你已经收获了mxgate的配置与启动。
集群部署方式请见集群部署,mxbench配置方法请见mxbench - 1 准备
4.2.1 10w设备 10个指标
mxbench常用参数配置主要分为俩部分:全局配置与可插件化的局部配置。全局配置包含database、global两板块;可插件化的配置包含数据生成器generator、数据写入工具writer、数据查询工具benchmark。
由于本节主要目的为体验MatrixDB加载性能,因此对于mxbench的查询工具benchmark不以赘述。 benchmark相关信息请见mxbench - 2.2.5 benchmark
具体如下:
| 参数名 | 默认值 | 参数含义 |
|---|---|---|
| --database | 默认值为环境变量PG_DATABASE,如没有设置则是postgres | 目标数据库名 |
| --db-master-port | 实例的端口号,需与环境变量中配置的端口号一致 | |
| --db-user | 检查当前的用户名,并作为默认值 | 用户名 |
| --workplace | /tmp/mxbench | csv数据文件,query文件的目录 |
| --watch | true | 是否开启进程观察,默认开启 |
| --simultaneous-loading-and-query | false | 是否同时执行数据加载和查询。默认值false,先执行数据加载,执行完毕后再执行查询 |
| --table-name | 目标表名,默认值为空,必需手动指定 | |
| --tag-num | 25000 | 目标设备数目 |
| --metrics-type | float8 | 指标类型,只支持 "int4", "int8", "float4", "float8", 4种类型 |
| --total-metrics-count | 300 | 指标总数 |
| --ts-start | 生成数据时间戳起始时间 | |
| --ts-end | 生成数据时间戳终止时间 | |
| --ts-step-in-second | 1 | 每几秒采集一次指标 |
| --generator | telematics | 随机数据生成器,默认生成车联网场景的时序数据。你也可以选择从自己的数据文件读取数据且发送至mxgate加载,不生成任何数据也是被允许的 |
| --generator-batch-size | 1 | 在特定时间戳下,每个设备的各个指标的数据拆分为几条上传至集群。默认值为1,即不作拆分 |
| --generator-disorder-ratio | 0 | 延迟上报数据的比例。取值0~100。默认值为0, 即没有延迟上报的数据。 通过设置此参数,你可以根据你的需要来模拟实际时序场景的任何延迟上报状况 |
| --generator-empty-value-ratio | 90 | 每行数据的空值率。取值为0~100。 默认值为90,即90%的指标都将是空值。此参数是为了模拟实际时序场景中的空值情况 |
| --generator-randomness | OFF | 指标数据随机度。分为OFF/S/M/L四个级别。默认为OFF,即每行数据值相同。SMALL、MIDDLE、LARGE级别的数据随机度按顺序依次增大 |
| --writer | http | 数据写入工具。可以选择以何种模式启动mxgate,并从数据源接收数据。 |
你可以在mxbench - 2 用法中找到更多可以配置的参数,或在命令行输入 mxbench --help 查看完整用法。
使用以下命令行来配置并运行mxbench,请参考上述表格并根据实际情况对参数值进行调整。由于mxgate和mxbench部署在一台机器上时候,writer工具使用“stdin”不用建立网络连接、通过网络传输,而可以直接利用Linux系统提供的管道,因此我们在示例中使用“stdin”参数,轻量便捷。
[mxadmin@mdw ~]$ mxbench run \
--db-database "load_test" \
--db-master-port 5432 \
--db-master-host "mdw" \
--db-user "mxadmin" \
--workspace "/tmp/mxbench/workspace" \
--watch \
--simultaneous-loading-and-query \
--table-name "test_table" \
--tag-num 100000 \
--metrics-type "float8" \
--total-metrics-count 10 \
--ts-start "2022-04-19 00:00:00" \
--ts-end "2022-04-19 00:01:00" \
--generator "telematics" \
--generator-batch-size 1 \
--generator-disorder-ratio 0 \
--generator-empty-value-ratio 0 \
--generator-randomness "OFF" \
--writer "stdin" 如果你未设置watch为“false”,则运行过程中可以每5秒的间隔实时看到进度信息,完成后得到以下统计信息:
┌───────────────────────────────────────────────────────┐
│ Summary Report for STDIN Writer │
├─────────────────────────────────┬─────────────────────┤
│ start time: │ 2022-07-21 15:14:08 │
├─────────────────────────────────┼─────────────────────┤
│ stop time: │ 2022-07-21 15:14:27 │
├─────────────────────────────────┼─────────────────────┤
│ size written to MxGate (bytes): │ 695333400 │
├─────────────────────────────────┼─────────────────────┤
│ lines inserted: │ 6000000 │
├─────────────────────────────────┼─────────────────────┤
│ compress ratio: │ 5.399120 : 1 │
└─────────────────────────────────┴─────────────────────┘ wirter统计报告输出解读:
| 参数名 | 参数含义 |
|---|---|
| start time | 数据加载起始时间 |
| end time | 数据加载终止时间 |
| size written to MxGate (bytes) | 向mxgate写入数据的字节数 |
| lines inserted | 插入数据的条数(行数) |
| compress ratio | 压缩比,即向mxgate写入数据的大小和实际数据库中该表的大小的比值 |
实际运行时间与整体加载的数据量,以及机器性能有关。只要没有关掉watch,你都可以以5s的间隔实时看到数据写入的进度信息,时刻掌握写入速度与时间!
注意!
mxbench启动后会持续压测,直到时间戳值从 ts-start 到 ts-end 的数据全部加载完毕。你也可以选择在键盘按下 ctrl-c 提前结束运行。
如果你觉得直接写大篇幅的命令行过于繁杂,也可以选择以下方式:创建配置文件mxbench.conf,将参数写进去,然后运行它。
[mxadmin@mdw ~]$ mxbench --config mxbench.conf注意!
你可能会在写入数据时遇到“卡住”的问题,此时进度信息会持续打印,但没有任何实质性的写入进度。不要慌张,可以运行以下语句查看运行日志,排查问题。[mxadmin@mdw ~]$ cd ~/gpAdminLogs/
4.2.2 10w设备 100个指标
[mxadmin@mdw ~]$ mxbench run \
--db-database "load_test" \
--db-master-port 5432 \
--db-master-host "mdw" \
--db-user "mxadmin" \
--workspace "/tmp/mxbench/workspace" \
--watch \
--simultaneous-loading-and-query \
--table-name "test_table2" \
--tag-num 100000 \
--metrics-type "float8" \
--total-metrics-count 100 \
--ts-start "2022-04-19 00:00:00" \
--ts-end "2022-04-19 00:01:00" \
--generator "telematics" \
--generator-batch-size 1 \
--generator-disorder-ratio 0 \
--generator-empty-value-ratio 0 \
--generator-randomness "OFF" \
--writer "stdin" 完成后得到以下统计信息:
┌───────────────────────────────────────────────────────┐
│ Summary Report for STDIN Writer │
├─────────────────────────────────┬─────────────────────┤
│ start time: │ 2022-07-21 15:19:48 │
├─────────────────────────────────┼─────────────────────┤
│ stop time: │ 2022-07-21 15:21:02 │
├─────────────────────────────────┼─────────────────────┤
│ size written to MxGate (bytes): │ 5555333400 │
├─────────────────────────────────┼─────────────────────┤
│ lines inserted: │ 6000000 │
├─────────────────────────────────┼─────────────────────┤
│ compress ratio: │ 25.519937 : 1 │
└─────────────────────────────────┴─────────────────────┘
4.2.3 10w设备 1000个指标
[mxadmin@mdw ~]$ mxbench run \
--db-database "load_test" \
--db-master-port 5432 \
--db-master-host "mdw" \
--db-user "mxadmin" \
--workspace "/tmp/mxbench/workspace" \
--watch \
--simultaneous-loading-and-query \
--table-name "test_table3" \
--tag-num 100000 \
--metrics-type "float8" \
--total-metrics-count 1000 \
--ts-start "2022-04-19 00:00:00" \
--ts-end "2022-04-19 00:01:00" \
--generator "telematics" \
--generator-batch-size 1 \
--generator-disorder-ratio 0 \
--generator-empty-value-ratio 0 \
--generator-randomness "OFF" \
--writer "stdin" 完成后得到以下统计信息:
┌───────────────────────────────────────────────────────┐
│ Summary Report for STDIN Writer │
├─────────────────────────────────┬─────────────────────┤
│ start time: │ 2022-07-21 15:22:27 │
├─────────────────────────────────┼─────────────────────┤
│ stop time: │ 2022-07-21 15:33:40 │
├─────────────────────────────────┼─────────────────────┤
│ size written to MxGate (bytes): │ 54305333400 │
├─────────────────────────────────┼─────────────────────┤
│ lines inserted: │ 6000000 │
├─────────────────────────────────┼─────────────────────┤
│ compress ratio: │ 47.488209 : 1 │
└─────────────────────────────────┴─────────────────────┘根据上述writer统计报告,我们向你提供一份更加直观的折线图对比,你可以在图中清晰了解到MatrixDB强大的数据加载性能,以及它随着指标规模会呈现一种怎样的增长,在实际场景运用中对于设定多少指标更加胸有成竹。
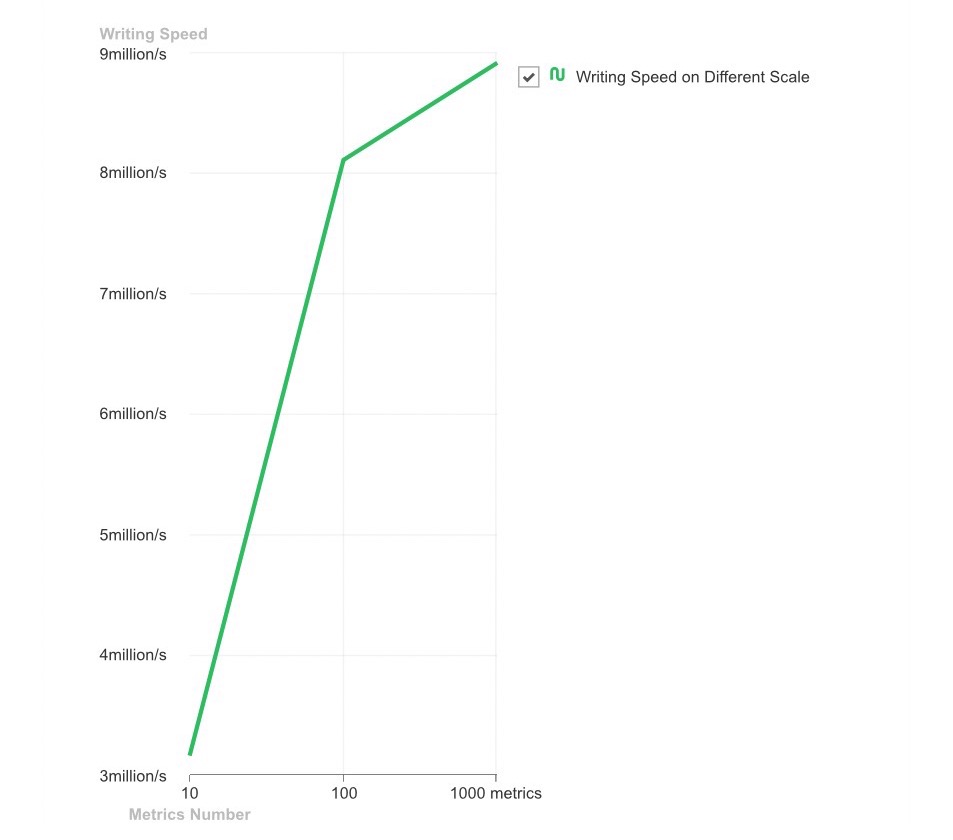
时序场景中的数据是带有时间戳属性的数据点,表示某个时间时刻某个指标的值,如果丢弃时间戳属性,就不可以称之为是时序场景下的数据。理解了数据点的概念,你可以更好地理解上图。图中横轴为用例中设定的不同指标规模,对应参数 total-metrics-count,纵轴为写入速度,表示每秒单位时间内可以写入数据点的数量,你肯定已经明白,随着指标规模的扩大,写入速度呈现出一种非常快速的增长,但如果指标数据较多,速度增长也会较为受限。不过无论怎样,MatrixDB的写入速度都是百万级的,比起苦着脸使用INSERT语句一条一条插入,何不尝试开着MarixDB在高速公路上驰骋一把!