故障恢复
MatrixDB是一款高可用的分布式数据库系统,支持在节点宕机后进行故障恢复。高可用的前提是冗余部署,所以master节点需要有standby节点作为备份;对于segment节点,primary为主节点,需要有与其对应的mirror节点。一个高可用系统的部署图如下所示:
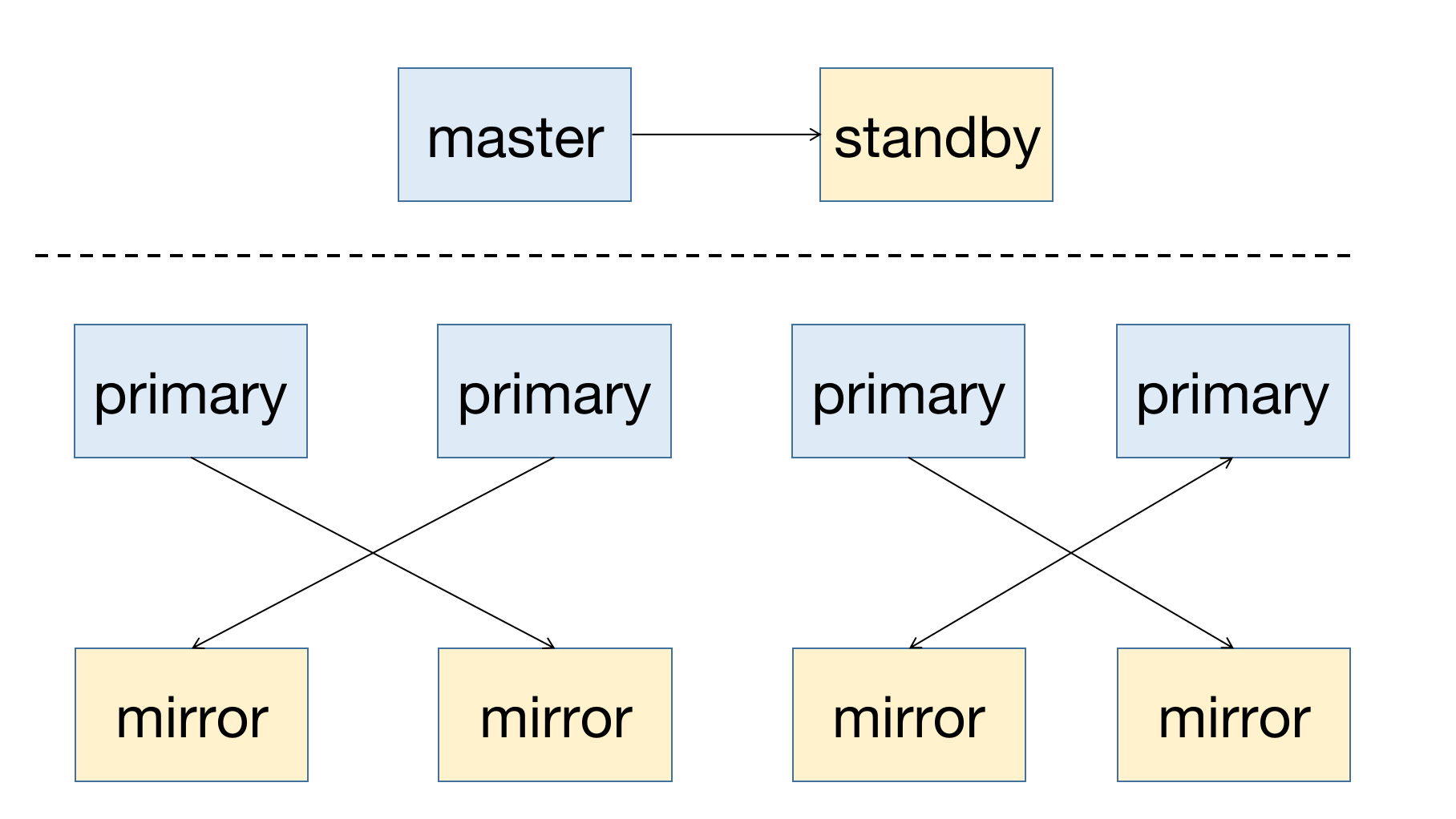
无论是master节点还是segment节点,其对应的备份节点都要部署到不同的主机上,以防止单主机故障导致集群不可用。
1. segment节点的故障诊断与恢复
1.1 FTS故障诊断服务
FTS(Fault Tolerance Service)是master节点的附属进程,用来管理segment节点的状态。当segment节点(primary或mirror)出现故障时,FTS进程会自动做故障恢复,可以通过查询gp_segment_configuration表来获取节点状态:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+----------+---------+-------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | p | p | s | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | s | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)列描述如下:
| 列名 | 描述 |
|---|---|
| dbid | 节点ID,从1递增 |
| content | 主从节点对编号,master和standby为-1 segment节点对从0递增 |
| role | 节点角色,p为主,m为从 |
| preferred_role | 节点初始角色 |
| mode | 同步情况 |
| status | 节点状态,u为存活,d为宕机 |
| port | 端口 |
| hostname | 主机名 |
| address | 主机地址 |
| datadir | 数据目录 |
从部署的情况可以看到:
- master和standby分别部署在不同独立节点上
- 每个segment的主和从部署在不同节点上
- segment的主节点是分散部署的
如上部署方式,目的就是避免单主机故障导致系统不可用,同时分散集群压力。
1.1.1 mirror节点宕机
当FTS发现mirror节点宕机,会在gp_segment_configuration表里标记节点状态为d。
因为mirror宕机并不会导致集群不可用,所以FTS不会做其他操作,重新激活mirror需要
gprecoverseg命令,后面会讲解。
从如下查询可以看到,当dbid=4的mirror节点宕机后,其状态变为d。
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+----------+---------+-------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | p | p | n | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | n | d | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)1.1.2 primary节点宕机
当FTS发现primary节点宕机,则会promote对应的mirror节点为primary。通过查询gp_segment_configuration表可以看到,节点的角色发生了变化,状态也随之改变。
从如下查询可以看到,dbid=2的primary节点宕机后,其对应的dbid=4的mirror节点被promote成primary。content=0的segment对,role与preferred_role已不相等,说明角色已经不是初始角色,并且节点状态产生了相应的变化。
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+----------+---------+-------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | m | p | n | d | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | p | m | n | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)1.2 gprecoverseg节点恢复工具
FTS会诊断segment节点状态,并在primary宕机时做主备切换。但是在主备切换后,对应的segment节点对则仅存primary,如果再出现故障,则无法恢复。所以,需要为新的primary再次生成mirror节点。这时就要用到gprecoverseg工具了。
gprecoverseg工具有如下作用:
- 将宕机的mirror节点重新激活
- 为promote成primary的节点,生成新的mirror
- 做节点角色的重分布,使其与初始角色一致
1.2.1 激活宕机mirror/生成新的mirror
直接执行gprecoverseg,即可激活宕机mirror:
[mxadmin@mdw ~]$ gprecoverseg
20210908:14:40:18:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Starting gprecoverseg with args:
20210908:14:40:18:012136 gprecoverseg:mdw:mxadmin-[INFO]:-local Greenplum Version: 'postgres (MatrixDB) 4.2.0-community (Greenplum Database) 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d'
20210908:14:40:18:012136 gprecoverseg:mdw:mxadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 12 (MatrixDB 4.2.0-community) (Greenplum Database 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5), 64-bit compiled on Sep 1 2021 03:15:53'
20210908:14:40:18:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Obtaining Segment details from master...
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Heap checksum setting is consistent between master and the segments that are candidates for recoverseg
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Greenplum instance recovery parameters
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery type = Standard
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery 1 of 1
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Synchronization mode = Incremental
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance host = sdw2
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance address = sdw2
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance directory = /mxdata/mirror/mxseg0
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance port = 6001
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance host = sdw1
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance address = sdw1
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance directory = /mxdata/primary/mxseg0
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance port = 6000
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Target = in-place
20210908:14:40:19:012136 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
Continue with segment recovery procedure Yy|Nn (default=N):
> y
20210908:14:40:20:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Starting to modify pg_hba.conf on primary segments to allow replication connections
20210908:14:40:23:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Successfully modified pg_hba.conf on primary segments to allow replication connections
20210908:14:40:23:012136 gprecoverseg:mdw:mxadmin-[INFO]:-1 segment(s) to recover
20210908:14:40:23:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Ensuring 1 failed segment(s) are stopped
20210908:14:40:24:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Updating configuration with new mirrors
20210908:14:40:24:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Updating mirrors
20210908:14:40:24:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Running pg_rewind on required mirrors
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Starting mirrors
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-era is 494476b1be478047_210908141632
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Commencing parallel segment instance startup, please wait...
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Process results...
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Triggering FTS probe
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Updating segments for streaming is completed.
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-For segments updated successfully, streaming will continue in the background.
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-Use gpstate -s to check the streaming progress.
20210908:14:40:25:012136 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************1.2.2 节点角色重分布
在primary节点宕机,FTS完成mirror的promote后,执行gprecoverseg可以为新的primary生成对应的mirror。这时查询gp_segment_configuration表:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+----------+---------+-------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | m | p | s | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | p | m | s | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)可以看到,对于content=0的segment节点对,primary和mirror都是活跃状态。但是,当前角色与初始角色已经发生了互换。那是因为mirror被转换成primary节点后,再进行gprecoverseg后,新的mirror节点复用了原来宕机的primary节点。
虽然gprecoverseg为新的primary节点重新生成了mirror,但是也带来了一个新问题,primary节点分布关系发生了变化,两个primary节点都分布在了sdw2上。这样会导致:
- 主机资源分配不均匀,sdw2会承载更多的压力
- 如果sdw2再宕机,受影响面太大
所以,要做主从的重分布,这也体现了preferred_role列的作用,记录初始角色。
重分布命令如下:
[mxadmin@mdw ~]$ gprecoverseg -r
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Starting gprecoverseg with args: -r
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-local Greenplum Version: 'postgres (MatrixDB) 4.2.0-community (Greenplum Database) 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d'
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 12 (MatrixDB 4.2.0-community) (Greenplum Database 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5), 64-bit compiled on Sep 1 2021 03:15:53'
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Obtaining Segment details from master...
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Greenplum instance recovery parameters
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery type = Rebalance
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Unbalanced segment 1 of 2
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance host = sdw2
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance address = sdw2
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance directory = /mxdata/mirror/mxseg0
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance port = 6001
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Balanced role = Mirror
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Current role = Primary
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Unbalanced segment 2 of 2
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance host = sdw1
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance address = sdw1
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance directory = /mxdata/primary/mxseg0
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Unbalanced instance port = 6000
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Balanced role = Primary
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Current role = Mirror
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[WARNING]:-This operation will cancel queries that are currently executing.
20210908:15:24:04:012918 gprecoverseg:mdw:mxadmin-[WARNING]:-Connections to the database however will not be interrupted.
Continue with segment rebalance procedure Yy|Nn (default=N):
> y
20210908:15:24:05:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Getting unbalanced segments
20210908:15:24:05:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Stopping unbalanced primary segments...
20210908:15:24:06:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Triggering segment reconfiguration
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Starting segment synchronization
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-=============================START ANOTHER RECOVER=========================================
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-local Greenplum Version: 'postgres (MatrixDB) 4.2.0-community (Greenplum Database) 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d'
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 12 (MatrixDB 4.2.0-community) (Greenplum Database 7.0.0+dev.17004.g36dd1f65d9 build commit:36dd1f65d9ceb770077d5d1b18d5b34d1a472c7d) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5), 64-bit compiled on Sep 1 2021 03:15:53'
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Obtaining Segment details from master...
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Heap checksum setting is consistent between master and the segments that are candidates for recoverseg
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Greenplum instance recovery parameters
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery type = Standard
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Recovery 1 of 1
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Synchronization mode = Incremental
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance host = sdw2
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance address = sdw2
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance directory = /mxdata/mirror/mxseg0
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Failed instance port = 6001
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance host = sdw1
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance address = sdw1
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance directory = /mxdata/primary/mxseg0
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Source instance port = 6000
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:- Recovery Target = in-place
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:----------------------------------------------------------
20210908:15:24:13:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Starting to modify pg_hba.conf on primary segments to allow replication connections
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Successfully modified pg_hba.conf on primary segments to allow replication connections
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-1 segment(s) to recover
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Ensuring 1 failed segment(s) are stopped
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Updating configuration with new mirrors
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Updating mirrors
20210908:15:24:16:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Running pg_rewind on required mirrors
20210908:15:24:17:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Starting mirrors
20210908:15:24:17:012918 gprecoverseg:mdw:mxadmin-[INFO]:-era is 494476b1be478047_210908141632
20210908:15:24:17:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Commencing parallel segment instance startup, please wait...
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Process results...
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Triggering FTS probe
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Updating segments for streaming is completed.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-For segments updated successfully, streaming will continue in the background.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Use gpstate -s to check the streaming progress.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-==============================END ANOTHER RECOVER==========================================
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-The rebalance operation has completed successfully.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-There is a resynchronization running in the background to bring all
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-segments in sync.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-Use gpstate -e to check the resynchronization progress.
20210908:15:24:18:012918 gprecoverseg:mdw:mxadmin-[INFO]:-******************************************************************当执行了gprecoverseg -r后,再查询数据库:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+----------+---------+-------------------------
1 | -1 | p | p | n | u | 5432 | mdw | mdw | /mxdata/master/mxseg-1
6 | -1 | m | m | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | p | p | n | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | n | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)可以看到,content=0的segment节点对的角色又恢复到了初始状态。
gprecoverseg的详细使用方法请参考文档
2. master节点的故障恢复
如果master节点出现了宕机,则数据库将无法建立连接与使用,只能激活standby节点作为新的master节点。
2.1 激活standby
激活方法如下:
[mxadmin@smdw ~]$ export PGPORT=5432
[mxadmin@smdw ~]$ export MASTER_DATA_DIRECTORY=/mxdata/standby/mxseg-1
[mxadmin@smdw ~]$ gpactivatestandby -d /mxdata/standby/mxseg-1
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Running Command: ps -ef | grep 'postgres -D /mxdata/standby/mxseg-1' | grep -v grep
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Standby data directory = /mxdata/standby/mxseg-1
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Standby port = 5432
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Standby running = yes
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Force standby activation = no
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:30:37:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Running Command: cat /tmp/.s.PGSQL.5432.lock
Do you want to continue with standby master activation? Yy|Nn (default=N):
> y
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Running Command: ps -ef | grep 'postgres -D /mxdata/standby/mxseg-1' | grep -v grep
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-found standby postmaster process
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Promoting standby...
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Running Command: pg_ctl promote -D /mxdata/standby/mxseg-1
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Waiting for connection...
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Standby master is promoted
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Reading current configuration...
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[DEBUG]:-Connecting to db template1 on host localhost
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-The activation of the standby master has completed successfully.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-smdw is now the new primary master.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-You will need to update your user access mechanism to reflect
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-the change of master hostname.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Do not re-start the failed master while the fail-over master is
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-operational, this could result in database corruption!
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-MASTER_DATA_DIRECTORY is now /mxdata/standby/mxseg-1 if
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-this has changed as a result of the standby master activation, remember
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-to change this in any startup scripts etc, that may be configured
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-to set this value.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-MASTER_PORT is now 5432, if this has changed, you
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-may need to make additional configuration changes to allow access
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-to the Greenplum instance.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Refer to the Administrator Guide for instructions on how to re-activate
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-the master to its previous state once it becomes available.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-Query planner statistics must be updated on all databases
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-following standby master activation.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:-When convenient, run ANALYZE against all user databases.
20210908:15:30:39:004123 gpactivatestandby:smdw:mxadmin-[INFO]:------------------------------------------------------激活standby后,查询数据库,可以看到原来的standby节点变成了master,并且没有新的standby节点:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+----------+---------+-------------------------
6 | -1 | p | p | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
2 | 0 | p | p | s | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | s | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(5 rows)2.2 初始化standby
standby激活成master后,需要为新的master节点再生成对应的standby备份,以防止再次宕机。
初始化standby需要使用gpinitstandby命令。
如下命令在mdw上的/home/mxadmin/standby目录,初始化一个运行端口为5432的standby节点:
[mxadmin@smdw ~]$ gpinitstandby -s mdw -S /home/mxadmin/standby -P 5432
20210908:15:38:54:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Validating environment and parameters for standby initialization...
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Checking for data directory /home/mxadmin/standby on mdw
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum standby master initialization parameters
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:------------------------------------------------------
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum master hostname = smdw
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum master data directory = /mxdata/standby/mxseg-1
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum master port = 5432
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum standby master hostname = mdw
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum standby master port = 5432
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum standby master data directory = /home/mxadmin/standby
20210908:15:38:55:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Greenplum update system catalog = On
Do you want to continue with standby master initialization? Yy|Nn (default=N):
> y
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Syncing Greenplum Database extensions to standby
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[WARNING]:-Syncing of Greenplum Database extensions has failed.
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[WARNING]:-Please run gppkg --clean after successful standby initialization.
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Adding standby master to catalog...
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Database catalog updated successfully.
20210908:15:38:56:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Updating pg_hba.conf file...
20210908:15:38:58:004367 gpinitstandby:smdw:mxadmin-[INFO]:-pg_hba.conf files updated successfully.
20210908:15:38:59:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Starting standby master
20210908:15:38:59:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Checking if standby master is running on host: mdw in directory: /home/mxadmin/standby
20210908:15:39:00:004367 gpinitstandby:smdw:mxadmin-[INFO]:-MasterStart pg_ctl cmd is env GPSESSID=0000000000 GPERA=None $GPHOME/bin/pg_ctl -D /home/mxadmin/standby -l /home/mxadmin/standby/log/startup.log -t 600 -o " -p 5432 -c gp_role=dispatch " start
20210908:15:39:01:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Cleaning up pg_hba.conf backup files...
20210908:15:39:02:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Backup files of pg_hba.conf cleaned up successfully.
20210908:15:39:02:004367 gpinitstandby:smdw:mxadmin-[INFO]:-Successfully created standby master on mdw初始化后,再查询数据库,可以看到,新的standby节点已生成:
mxadmin=# select * from gp_segment_configuration order by content,dbid;
dbid | content | role | preferred_role | mode | status | port | hostname | address | datadir
------+---------+------+----------------+------+--------+------+----------+---------+-------------------------
6 | -1 | p | p | s | u | 5432 | smdw | smdw | /mxdata/standby/mxseg-1
7 | -1 | m | m | s | u | 5432 | mdw | mdw | /home/mxadmin/standby
2 | 0 | p | p | s | u | 6000 | sdw1 | sdw1 | /mxdata/primary/mxseg0
4 | 0 | m | m | s | u | 6001 | sdw2 | sdw2 | /mxdata/mirror/mxseg0
3 | 1 | p | p | s | u | 6000 | sdw2 | sdw2 | /mxdata/primary/mxseg1
5 | 1 | m | m | s | u | 6001 | sdw1 | sdw1 | /mxdata/mirror/mxseg1
(6 rows)gpinitstandby的详细使用方法请参考文档
gpactivatestandby的详细使用方法请参考文档