YMatrix 文档
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
- MPP 架构
- 镜像分布策略
- 持续聚集
- 滑动窗口
- 全文搜索
- Grafana 监控指标解读
- Prometheus 监控指标解读
- 术语表
-
工具指南
- mxaddmirrors
- mxbackup
- mxbench
- mxdeletesystem
- mxgate
- mxinitstandby
- mxmoveseg
- mxpacklogs
- mxrecover
- mxrestore
- mxshift
- mxstart
- mxstate
- mxstop
- gpconfig
- pgvector
-
数据类型
-
存储引擎
-
执行引擎
-
系统配置参数
- 使用说明(必读)
- 参数目录
- 文件位置参数
- 连接与认证参数
- 客户端连接默认值参数
- 错误报告和日志参数
- 资源消耗参数
- 查询调优参数
- 运行中的统计信息参数
- 自动清理参数
- 数据表参数
- 锁管理参数
- 资源管理参数
- YMatrix 数据库集群参数
- 预写式日志参数
- 复制参数
- PL/JAVA 参数
- 版本和平台兼容性参数
-
索引
-
扩展
SQL 参考
- ABORT
- ALTER_DATABASE
- ALTER_EXTENSION
- ALTER_EXTERNAL_TABLE
- ALTER_FOREIGN_DATA_WRAPPER
- ALTER_FOREIGN_TABLE
- ALTER_FUNCTION
- ALTER_INDEX
- ALTER_RESOURCE_GROUP
- ALTER_RESOURCE_QUEUE
- ALTER_ROLE
- ALTER_RULE
- ALTER_SCHEMA
- ALTER_SEQUENCE
- ALTER_SERVER
- ALTER_TABLE
- ALTER_TABLESPACE
- ALTER_TYPE
- ALTER_USER_MAPPING
- ALTER_VIEW
- ANALYZE
- BEGIN
- CHECKPOINT
- COMMIT
- COPY
- CREATE_DATABASE
- CREATE_EXTENSION
- CREATE_EXTERNAL_TABLE
- CREATE_FOREIGN_DATA_WRAPPER
- CREATE_FOREIGN_TABLE
- CREATE_FUNCTION
- CREATE_INDEX
- CREATE_RESOURCE_GROUP
- CREATE_RESOURCE_QUEUE
- CREATE_ROLE
- CREATE_RULE
- CREATE_SCHEMA
- CREATE_SEGMENT_SET
- CREATE_SEQUENCE
- CREATE_SERVER
- CREATE_TABLE
- CREATE_TABLE_AS
- CREATE_TABLESPACE
- CREATE_TYPE
- CREATE_USER_MAPPING
- CREATE_VIEW
- DELETE
- DROP_DATABASE
- DROP_EXTENSION
- DROP_EXTERNAL_TABLE
- DROP_FOREIGN_DATA_WRAPPER
- DROP_FOREIGN_TABLE
- DROP_FUNCTION
- DROP_INDEX
- DROP_RESOURCE_GROUP
- DROP_RESOURCE_QUEUE
- DROP_ROLE
- DROP_RULE
- DROP_SCHEMA
- DROP_SEGMENT_SET
- DROP_SEQUENCE
- DROP_SERVER
- DROP_TABLE
- DROP_TABLESPACE
- DROP_TYPE
- DROP_USER_MAPPING
- DROP_VIEW
- END
- EXPLAIN
- GRANT
- INSERT
- LOAD
- LOCK
- REINDEX
- RELEASE_SAVEPOINT
- RESET
- REVOKE
- ROLLBACK_TO_SAVEPOINT
- ROLLBACK
- SAVEPOINT
- SELECT INTO
- SET ROLE
- SET TRANSACTION
- SET
- SHOW
- START TRANSACTION
- TRUNCATE
- UPDATE
- VACUUM
故障恢复
YMatrix 是一款高可用的分布式数据库系统,支持在节点宕机后进行故障恢复。高可用的前提是冗余部署,所以主节点(Master)需要有备用节点(Standby)作为备份;对于数据节点(Segment),Primary 为主节点,需要有与其对应的镜像节点(Mirror)。
一个高可用系统的部署图如下所示:
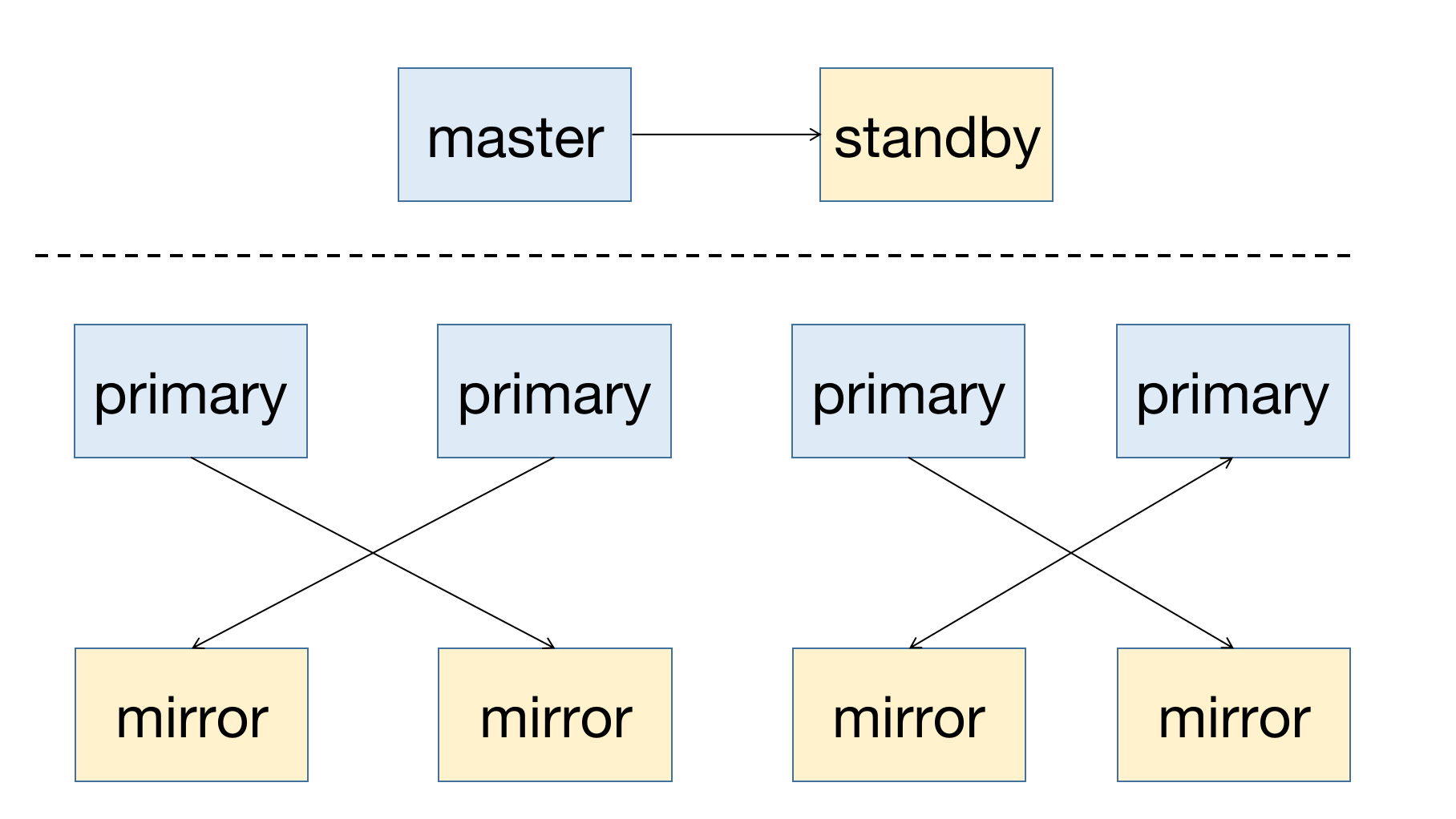
当集群中节点出现故障,你可以通过查看图形化界面(MatrixUI)来获取节点状态信息。示例集群 Master 为 mdw,Standby 为 smdw,Segment 为 sdw 1 与 sdw 2,二者各有一个 Mirror。
部署情况:
- Master 和 Standby 分别部署在不同独立节点上
- 每个 Segment 的主和从部署在不同节点上
- Segment 的主节点是分散部署的
如上部署方式,目的就是避免单主机故障导致系统不可用,同时分散集群压力。
下文将简单讲述 YMatrix 集群的自动运维原理及不同作用节点的宕机场景解决。
1 原理
YMatrix 支持集群状态服务(Cluster Service),用以运维自动化。此服务主要包含故障自动转移(Failover)及以 mxrecover 工具为支撑的故障自动恢复(Failback)两个功能。利用这两个功能,可以实现节点故障的完整恢复流程。
1.1 故障自动转移(Failover)
故障自动转移指自动运维体系中,通过调取 etcd 集群的节点状态诊断信息,切换主备节点从而转移故障的机制。etcd 集群是 YMatrix 集群状态服务中的核心组件,负责管理所有节点的状态信息。当集群中任一节点出现故障时,数据库系统会自动进行节点故障转移,无需人工干预。
1.2 故障自动恢复(Failback)
故障自动转移完成后,相应节点对仅存 Primary / Master,没有健康的备用节点。如果再出现故障,则无法恢复。所以,需要使用 mxrecover 工具为新的 Primary / Master 生成健康的 Mirror / Standby 节点。
mxrecover 工具有如下作用:
- 将宕机的 Mirror / Standby 节点重新激活
- 为提升成 Primary / Master 的节点,生成新的 Mirror / Standby
- 完成节点角色的重分布,使其与初始角色一致
注意!
mxrecover 工具的详细使用方法请见 mxrecover。
2 不同节点故障场景
2.1 Mirror / Standby 宕机
当系统发现 Mirror / Standby 宕机,图形化界面的节点状态会变为 down。
注意!
Mirror 宕机并不会导致集群不可用,因此系统不会重新激活 Mirror。
激活 Mirror 需要使用mxrecover工具,详见下文。
此时,如果距离宕机时间间隔较短,且宕机节点数据量规模不算很大,建议你先尝试增量恢复。当 mxrecover 命令后没有参数或者只有 -c 时,即使用增量恢复模式。如果增量恢复失败,则需要通过复制全量数据激活宕机节点,即使用 mxrecover -F 命令。
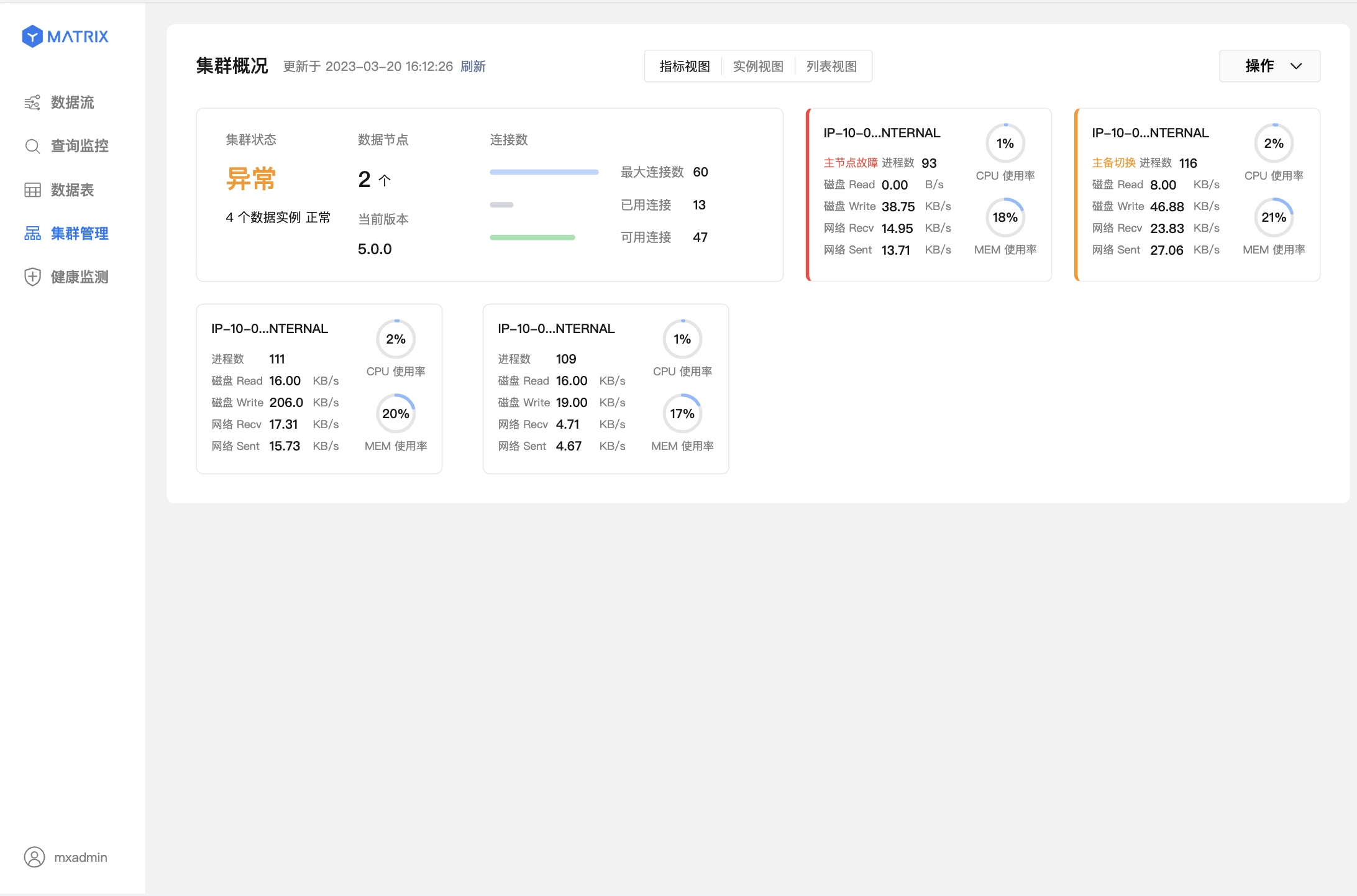
2.2 Primary / Master 节点宕机
当系统发现 Primary 宕机,则会自动提升对应的 Mirror 为 Primary。
下图表示主节点(Master)故障,已完成主备切换。方框左侧红色表示此节点故障,黄色表示此节点已完成故障转移。
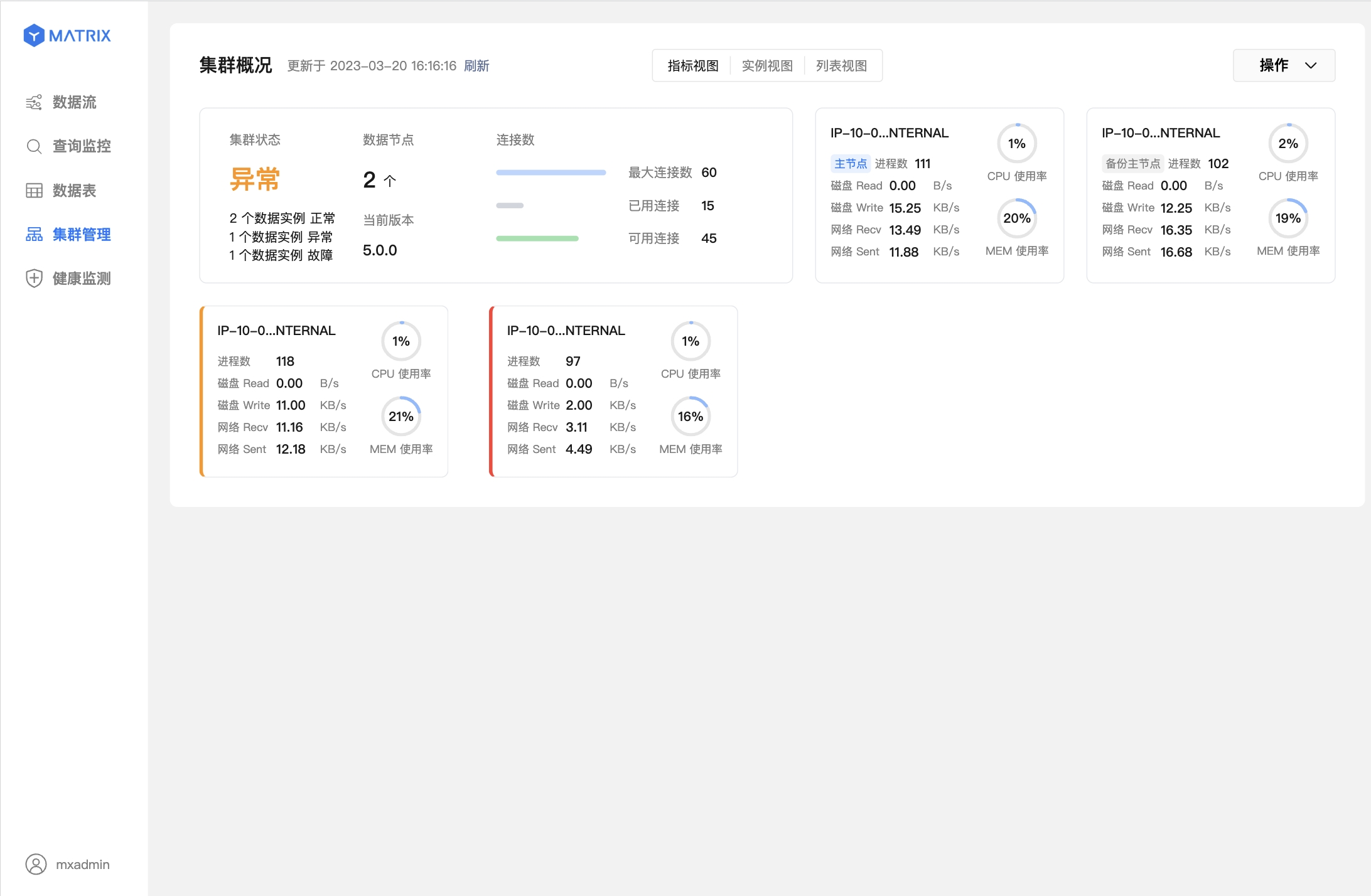
下面两个图则表示数据节点(Segment)故障,已完成主从切换。
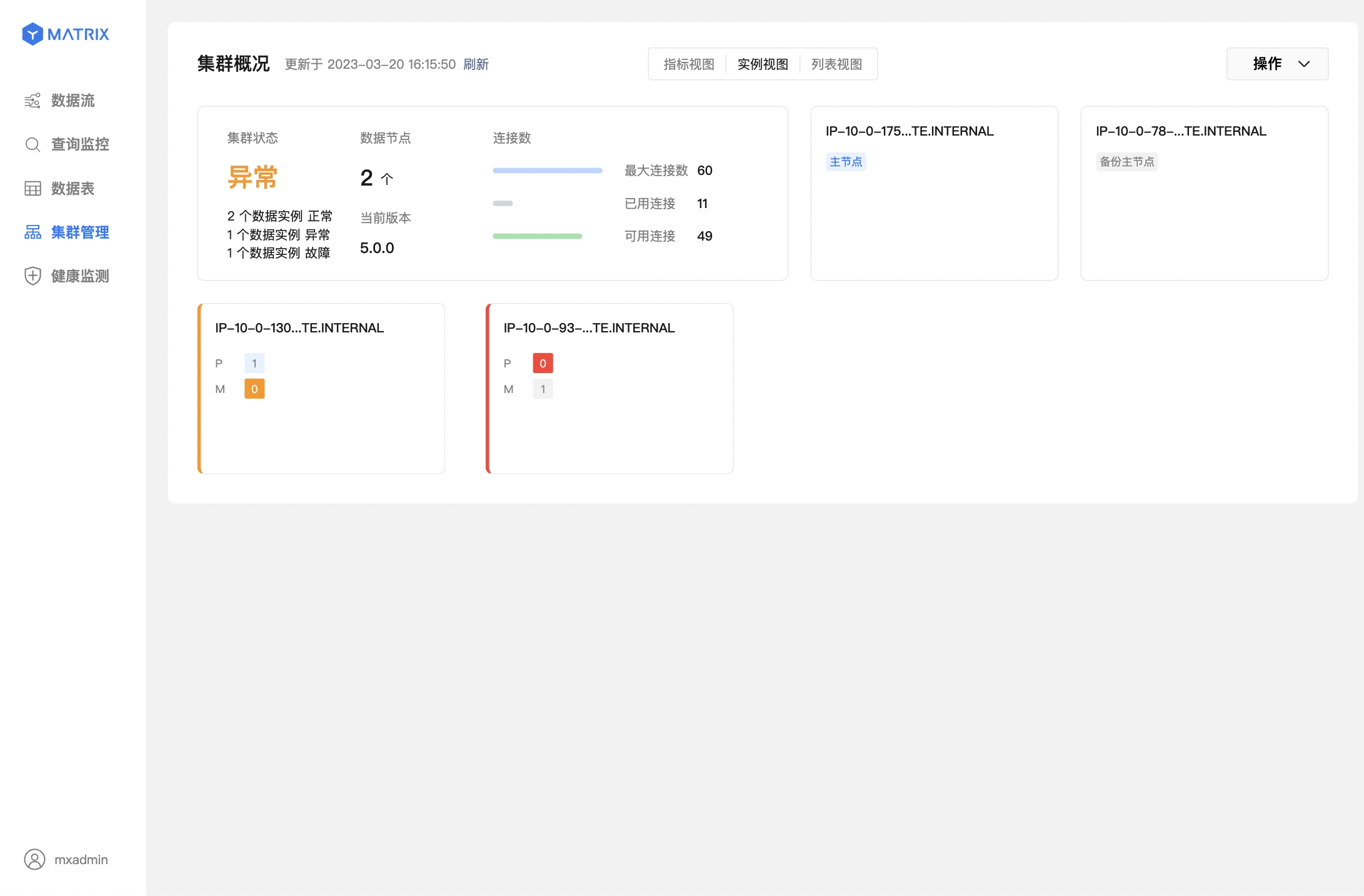
1.2.1 激活宕机 Mirror / Standby
在系统自动完成 Mirror / Standby 的提升后,执行 mxrecover 可以为新的 Primary / Master 生成对应的 Mirror / Standby,并全量或增量同步节点数据以恢复宕机节点。 直接执行 mxrecover,即可激活宕机 Mirror / Standby,增量恢复数据。如上文所述,如需全量恢复,则需要使用 mxrecover -F 命令强制执行。
[mxadmin@mdw ~]$ mxrecover1.2.2 节点角色重分布
虽然 mxrecover 为新的 Primary 节点重新生成了 Mirror,但是也带来了一个新问题,Primary 节点分布关系发生了变化,两个 Primary 节点都分布在了 sdw2 上。这样会导致主机资源分配不均匀,sdw2 也会承载更多的负载。
重分布命令如下:
[mxadmin@mdw ~]$ mxrecover -r当执行了 mxrecover -r 后,再进入图形化界面的集群管理页面进行检查即可。