导读:今天分享的主题和⼯程⻋辆的全周期智能运维解决⽅案有关,首先对基于传统的全周期智能运维方案进行一个概述,并基于传统架构的一些痛点提出我司研发的新产品——MatrixDB 超融合时序数据库的一些技术特点;最后简单介绍我司的 MatrixDB 生态。
今天的介绍会围绕下面三点展开:
-
工程车辆全周期智能运维传统架构
-
MatrixDB 超融合时序数据库
-
关于 MatrixDB
01 工程车辆全周期智能运维传统架构
1. ⼯程⻋辆简介
混凝⼟搅拌⻋、⾃卸⻋、压路机、混凝⼟泵⻋等专⽤于⼯程领域的⻋辆都可以被称为⼯程⻋辆。
得益于新基建的蓬勃发展,⼯程⻋辆⾏业已逐渐进⼊世界主舞台,三一、中联等⾏业⻰头企业已经在各自领域做到了世界第⼀。
然而,不同的⼯程⻋辆具备各自独特的功能;而每一种功能,一般也都具备各自独特的智能化手段,以及测试方法。
因此,相⽐于家⽤汽⻋,工程车辆的智能化还处于转型起步阶段。
对于企业内部而言,在新的领域如果⽆法迎头赶上,往往处于不翻身就翻盘的尴尬。
2. ⼯程⻋辆全周期智能运维简介
-
不同于家⽤汽⻋,⼯程⻋辆更多的定位是⽣产资料
-
客户一般不会亲自开车,而是雇佣司机与操作员来通过⻋辆完成指定的⼯程任务
-
客户往往管理车辆,会关⼼⻋辆的实时位置与健康状态、是否有偷油等现象发⽣
-
需要借由智能化的平台来获得客源、降低调度成本、评估⻋辆残值
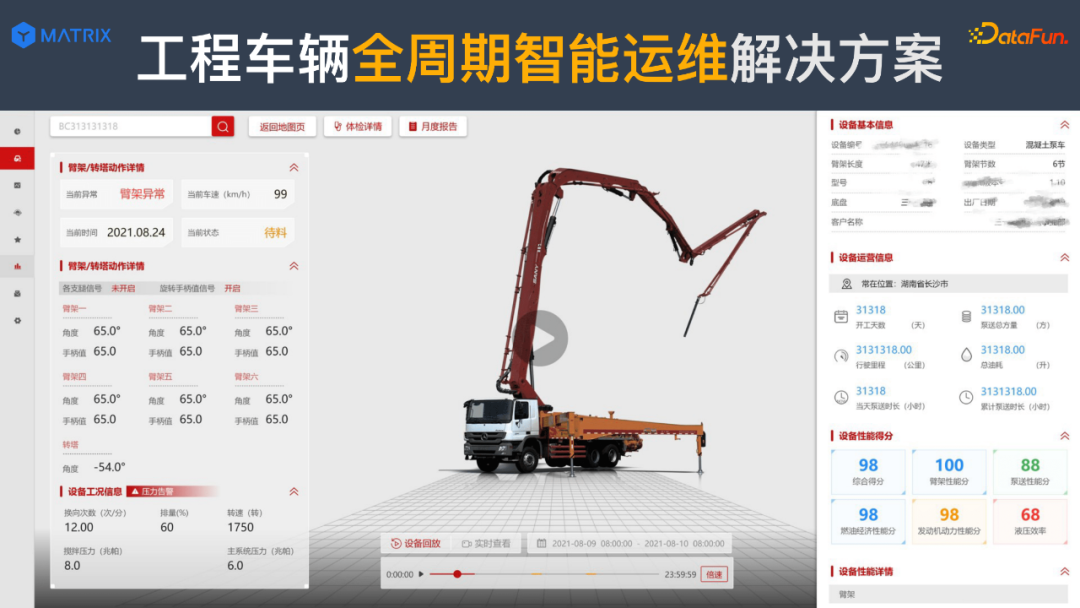
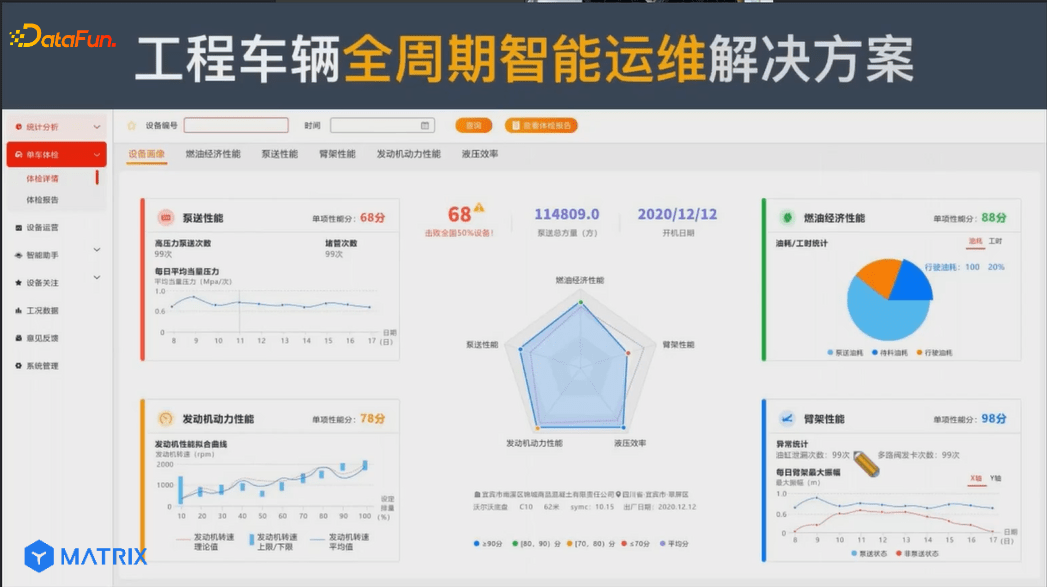
上图以泵车为例,从发动机的角度查看发动机的情况、泵车的情况、耗油的情况,以及对泵车的臂架、臂管等状态和稳定性的评估。
综上所述,对于工程车辆,客户关注重点主要在于:⻋辆健康状态、赚了多少钱、更多赚钱机会、⻋辆残值等。
3. ⼯程⻋辆全周期智能运维的传统架构实现
前文已经讲述了工程车辆全周期管理平台对于客户的价值;对于平台数据接入的现状如下:
-
⼤数据平台接⼊来⾃数万台设备的⼏千个⼯况参数的数据
-
每⽇回传数据在⼗亿条⾄百亿条左右
-
实现每天每台设备的指标计算、智能巡检、模型训练与时序数据展示
-
客户通常采⽤ Hadoop + Spark 的传统⼤数据架构
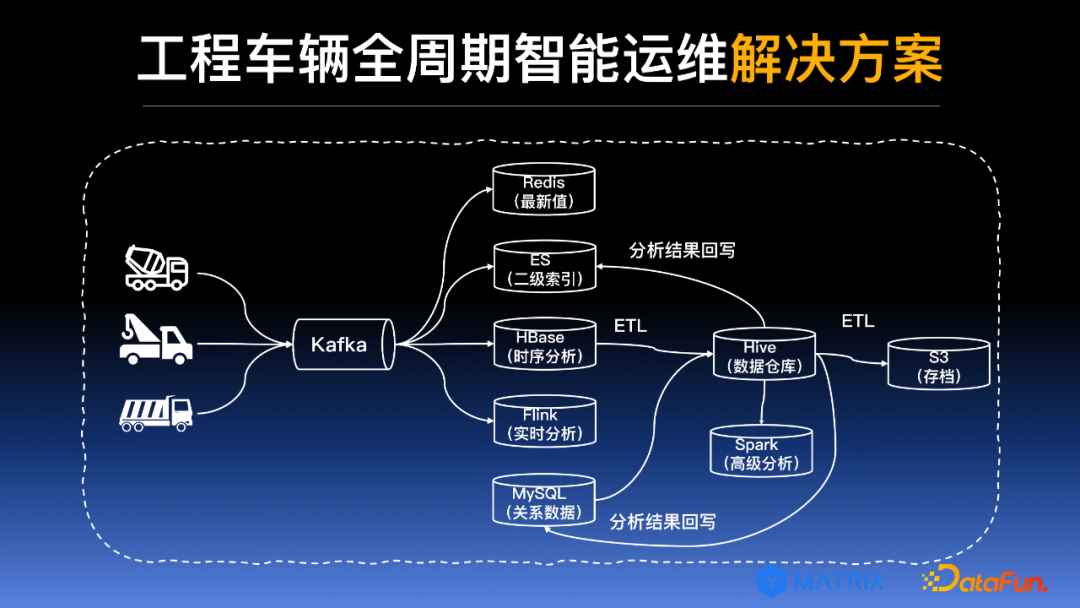
上图展示了一类典型的全周期管理平台内部架构图:
① 各种类型的原始车辆数据汇总传入 Kafka 进行数据汇总
-
数据一般通过4G信号传输
-
将回传信号基于数据的定义进行解析
-
解析的结果是固定格式的大量的 JSON 串
② Kafka 数据汇总结果可以传入多个组件进行不同功能的使用
-
传入 Redis 进行最新值查询
-
传入 ES 进行二级索引
-
传入 HBase 进行小规模时序分析(对于更大规模或者更高级的计算,一般使用会 Hive 或者 Spark)
-
传入 Flink 进行时序分析
③ 对于数据的中间分析结果,可存入 MySQL(或其他存档中)便于前后端交互
4. 全周期智能运维平台的痛点
前文讲述了客户常见的管理平台的内部架构整体情况;在工程应用中发现,该类平台架构存在如下诸多的痛点:
① 痛点一:复杂架构问题
架构复杂,会直接造成资源上的浪费;另一方面,数据从不同系统之间反复传递,会带来效率上的降低。
与此同时,从团队管理角度来看,架构复杂会导致招⼈难、养⼈难、留⼈难,给团队会带来成本压力。
② 痛点二:数据质量问题
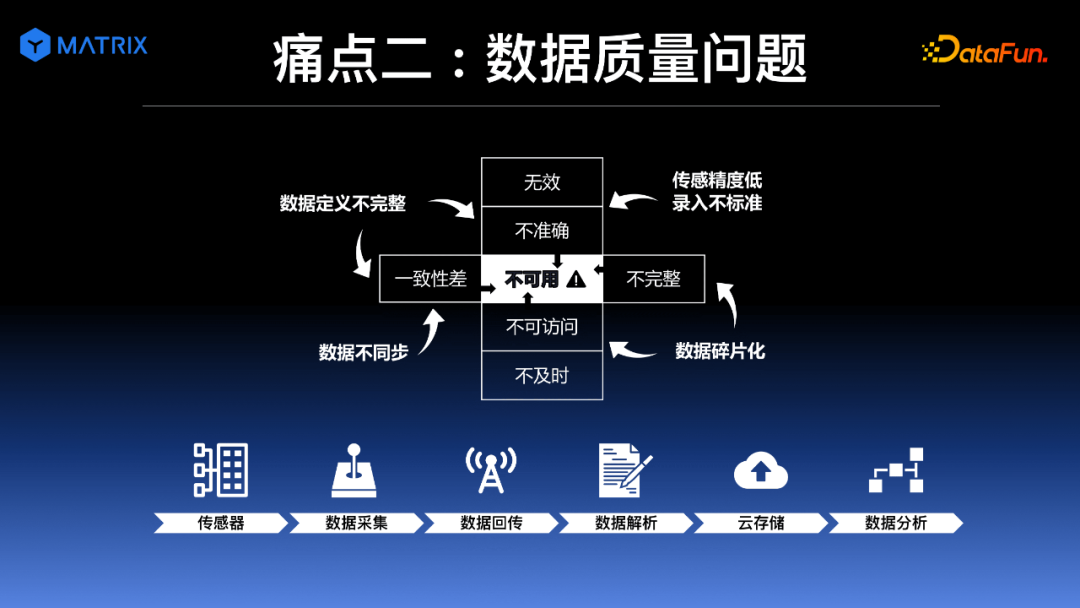
除了资源浪费问题,遇到的第二个比较严重的问题就是数据质量问题。所谓数据质量,主要指的是:数据满足需方的程度,包括数据格式、数据准确性、数据时间一致性等。这里会带来一系列的问题,比如数据的空值、乱序,数据时间间隔不统一,数据出现明显错值等问题,会严重影响后期数据的使用。
③ 痛点三:执⾏效率问题
Hadoop + Spark 这样的传统⼤数据架构更适合 map reduce 的场景;相较于早期基于 Hadoop 的 map reduce 架构,Spark 系统增加了懒加载模式,还增加了基于内存的计算。这样的处理确实使执行效率得到了一定程度的提高,然而对于大多数面向过程的工业计算,两者仍然难以实现很好的契合,比如算法思路连续性的保持等。最典型的体现是:对于分布式的 HDFS 系统,Spark 系统无法确定待处理数据的位置,因此每次在处理和分析数据之前,需要首先发出相应的请求来获取数据;这样随着整体数据量的积累,即使是⼩规模的数据验证也会需要较⻓时间的等待(目前系统使用的 Scala 语言;若使⽤的是 Python,则等待时间可能会更⻓)。
④ 痛点四:开发效率问题
除了系统的执行效率,开发效率也是一个大问题。这里从 Sublime 截取了 3 张代码图,可以看出存在大量的胶水代码;特别是在与 pandas UDF 的交互中,需要明确定义输入和输出文件的变量名、列名等,而且计算过程中也需要不断地对行和列进行索引,因此不可避免地出现非常多的胶水代码,大大增加了代码的开发和维护成本,降低了开发的效率。
02 MatrixDB 超融合时序数据库
1. MatrixDB 超融合时序数据库的提出——将复杂留给数据库
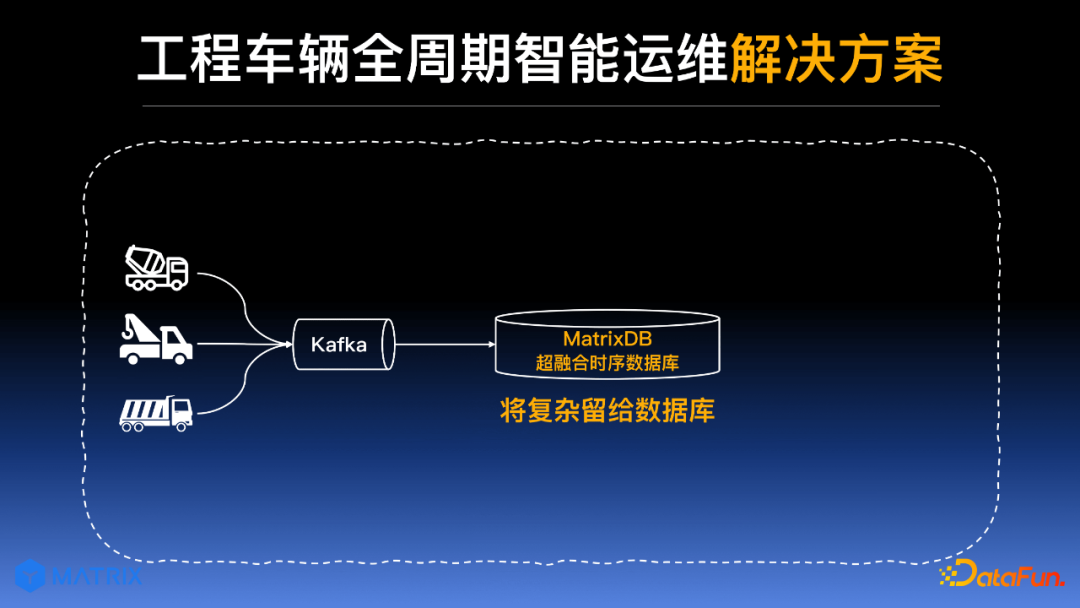
基于前文所述的诸多痛点,经过多轮调研和尝试,提出了 MatrixDB 超融合时序数据库,将复杂的分析和存储过程,通过一款数据库统一实现;从而减轻开发人员的工作量,让开发人员更少地参与数据治理的工作。
2. MatrixDB 基本架构设计
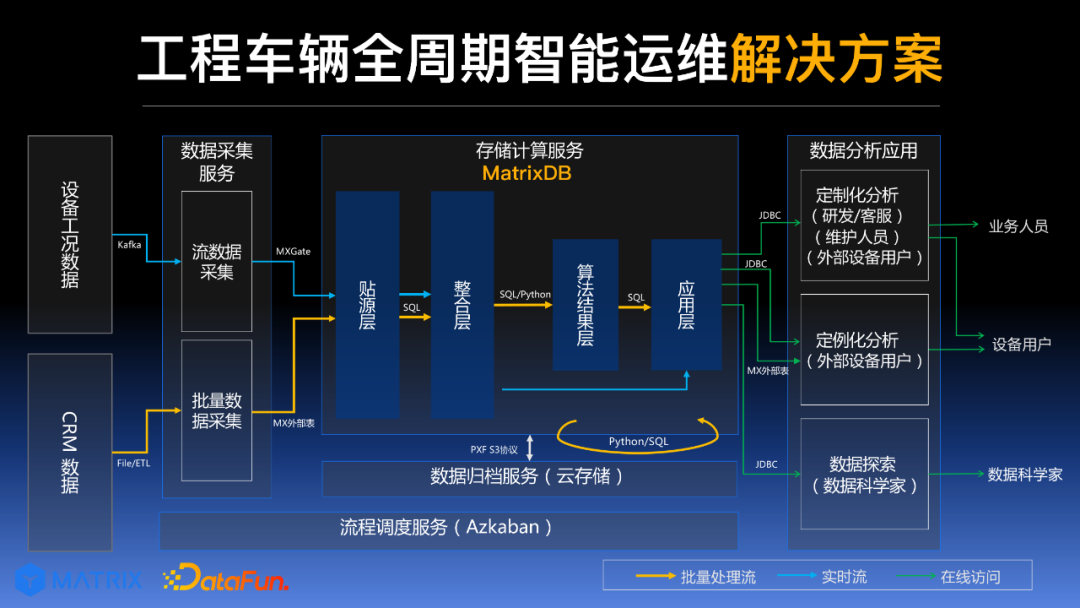
上图展示了 MatrixDB 超融合时序数据库的基本架构:
-
数据接入汇总到 Kafka 存储引擎,通过 MXGate 组件获取数据
-
数据的贴源层、整合层、算法结果层、应用层等均存储在 MatrixDB 超融合时序数据库内
这样,所有对涉及数据库有关的操作都可以在同一数据库内完成。例如,读取实时数据,只需向整合层发出请求即可;同理,读取后端数据,需向算法结果层发出请求。
3. MatrixDB 的功能优势
数据库查询中常用的 SQL 语言一种面向数据的查询语言,很难支持工业数据分析中常用的诸如 FFT 变换、小波变换等类型的分析;而常见的设备预测性维护、故障诊断等问题主要是面向过程的分析,因此不可避免地使用到 python/R 这类面向过程的分析语言。
在实施层面,可以考虑使用 pyspark 结合 pandas_UDF,不过前文已经讲述过这种方式的弊端:会带来大量的胶水代码,不利于系统的开发和维护。另一种方式就是在数据库中通过内建查询来实现(定义存储过程,并且把存储过程声明为外部的 plpython3u 语言;对于结果的存储,只需定义存储结果表,无需另行定义pandas结构);因此大大减少了胶水代码的使用,大大提高了开发效率;由于数据结构清晰,大大降低了获取数据请求的时间,使计算更贴近数据,更加高效简洁,这也是 MatrixDB 对比 Spark/Hive 的一大优势。
MatrixDB 的功能优势:
-
数据库内建查询,计算贴近数据,⾼效简洁
-
应⽤ Python/R/Java 代码原地处理库内海量数据,⼤量函数库⽀持,Pandas、Numpy 等
-
使⽤主流 AI 库对数据库内部海量数据原地训练和分析
-
可以通过 SQL 实现机器学习,包括监督学习、⽆监督学习、统计分析、图计算等
4.MatrixDB 的读写性能优势

从性能测试角度看,窄表单机每秒可写2200万⾏以上;数据可实现分钟级、秒级、甚至毫秒级的实时写入,这也是该全周期运维平台可以实现实时查询的基础,也是对比旧版本的一大改进。
从功能角度看,除了常规的顺序写⼊外,对于设备网络等因素带来的延迟写⼊、乱序写入,以及同设备多测点数据的分批写⼊(涉及数据更新、插入、合并等多种烦琐操作)等,MatrixDB 都可以实现良好的支持。
另一方面,在工程数据分析的过程中,经常会涉及到指标的调整;体现在数据库中,就是对表结构的动态增减调整。如果使用窄表,可以很容易地实现动态增减;然而窄表不利于后期数据的使用,这也是 MatrixDB 技术团队攻破的一大技术难题:在宽表的基础上增加对表结构动态增减的支持,同时保证写入和查询效率的不缺失。
此外,平台还可支持自动降采样(分层)功能,对将原始数据分层成中间结果,对中间结果进行进一步的分析,大大提升分析的效率。
平台还有一项功能值得一提:持续聚集。类似于 T+0 机制,用户可预设算法,该预设的算法作为一个固定的物化视图;随着数据的写入,自动计算结果并写入到指定表中。 最后一点,该平台提供丰富的工具支持(flink、kettle、nifi 等常用 ETL 工具),以及灵活的接⼝支持(SQL、JDBC、HTTP 等常用接口)。
总之,MatrixDB 数据库从源头着⼿实现数据治理,让用户聚焦业务本身⽽不是数据处理。
5. MatrixDB 的存储优势
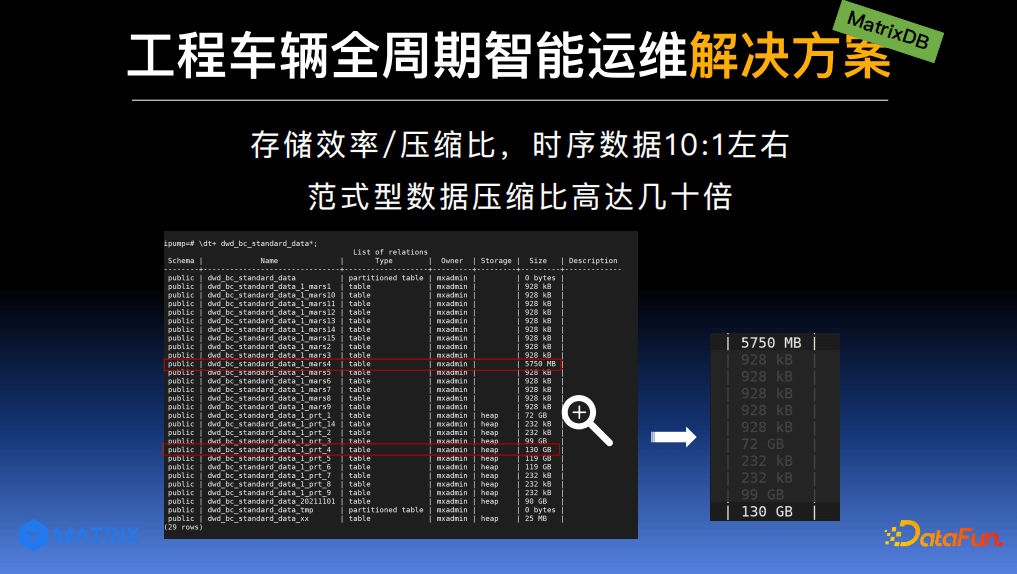
另一个用户经常关心的问题是数据量较大时的存储效率问题。从截图中可以看出,当原始数据量较大时,使用原始分区表,采用行式存储方式,占用空间达130G;同一张表改用 MatrixDB 数据库存储,占用空间仅5.75G,压缩比超过10倍。MatrixDB 数据库存储可以理解成一种特殊的列式存储,在存储之前基于指定的设备编号进行了排序功能。
6. MatrixDB 在工程车辆全周期智能运维解决方案应用的优势小结
客户通过智能运营平台对混凝⼟泵⻋进⾏智能化运维。实现的场景包括针对研发⼈员的决策⽀撑、针对服务⼈员的预测性维护以及针对客户的设备健康管理平台。平台⽬前接⼊了超过25000台设备。每天的数据量⼤于8亿条,有效指标400余列,指标包括控制稳定性、油耗分析、堵管分析等⼏⼗个。

上图展示了 MatrixDB 数据库系统在部署前后,从开发、功能和性能等方面的对比情况。相⽐于原先使用的传统系统:
-
MatrixDB 数据库系统提供了即时分析功能
-
定制化分析与算法开发周期缩短43%
-
运维⼈⼒投⼊降低30%
-
集群规模节省超43.75%
03 关于MatrixDB
1. MatrixDB 生态简介
MatrixDB 本身是基于 Greenplum 数据库和 PostgreSQL 数据库进行的优化,因此继承了上述两种数据库中的优点:标准 SQL 的丰富性,查询速度较快,并发数较高等。
Greenplum 数据库和 PostgreSQL 数据库的优点:
① 按表数量
-
单表:点查、明细、聚集,TPCB 单机60万 TPS
-
多表:多维分析,强⼤优化器,⽀持50+表关联;TPCH、TPCDS 性能卓越
② 按数据类型
-
时序类型查询:first, last, 窗⼝查询、⾮空最新值、协⽅差、标准差等
-
空间数据类型查询:范围查询、相交查询等
-
⽂本查询:前缀、后缀、模糊、索引
③ 按分析能⼒
-
⾼级分析型查询:⼦查询、窗⼝函数、数据⽴⽅体
-
机器学习模型训练和推理
另一方面,企业级平台常用的 Hadoop/Spark 等开源工具在使用的过程中经常出现版本不兼容等诸如此类的问题;MatrixDB 数据库系统很好地避免了这类麻烦,也与此同时还增加了方便易用的图形化部署、在线扩容等功能,可以单机部署,也可集群部署,具备了理想的企业级运维能力。
企业级运维平台:
-
在线扩容:不停机,不停业务
-
资源管理:CPU、内存、并发等
-
易⽤性:Kafka ⽀持、分钟级升级
-
监控:报警以及可视化,兼容 Grafana
-
容灾:分布式备份与恢复
此外,MatrixDB 数据库系统具备完善的开发⼯具,支持常用的协议;用户使用的过程中,除了需要单独维护一些分布式的功能外,其他方面和单机版数据库,在使用方式上没有区别;但是其性能更高,可管理的数据量更大。
MatrixDB 数据库系统的接口支持:
-
流⾏ IDE ⽀持:包括 IntelliJ、DataGrip、Dbeaver、Navicat 等
-
BI 和可视化:Grafana、Tableau、永洪、帆软、SAS、Cognos、Zabbix 等
-
ETL 和 CDC:Informatica、Talend、DSG、Datapipeline、HRV 等
-
物联⽹协议:MQTT、OPC-UA、OPC-DA、MODBUS 等
-
物联⽹平台:Node-Red、ThingsBoard
-
数据联邦:HDFS、Hive、HBase、S3、MongoDB、MySQL、PG、Oracle 等
2. MatrixDB 研发团队介绍
公司的MatrixDB研发团队的核心骨干成员主要来自 Greenplum 原⼚团队:
-
姚延栋:Greenplum 原北京研发中⼼总经理
-
⾼⼩明:Greenplum 原全球内核产品总监
-
翁岩⻘:Greenplum 原云原⽣总架构师
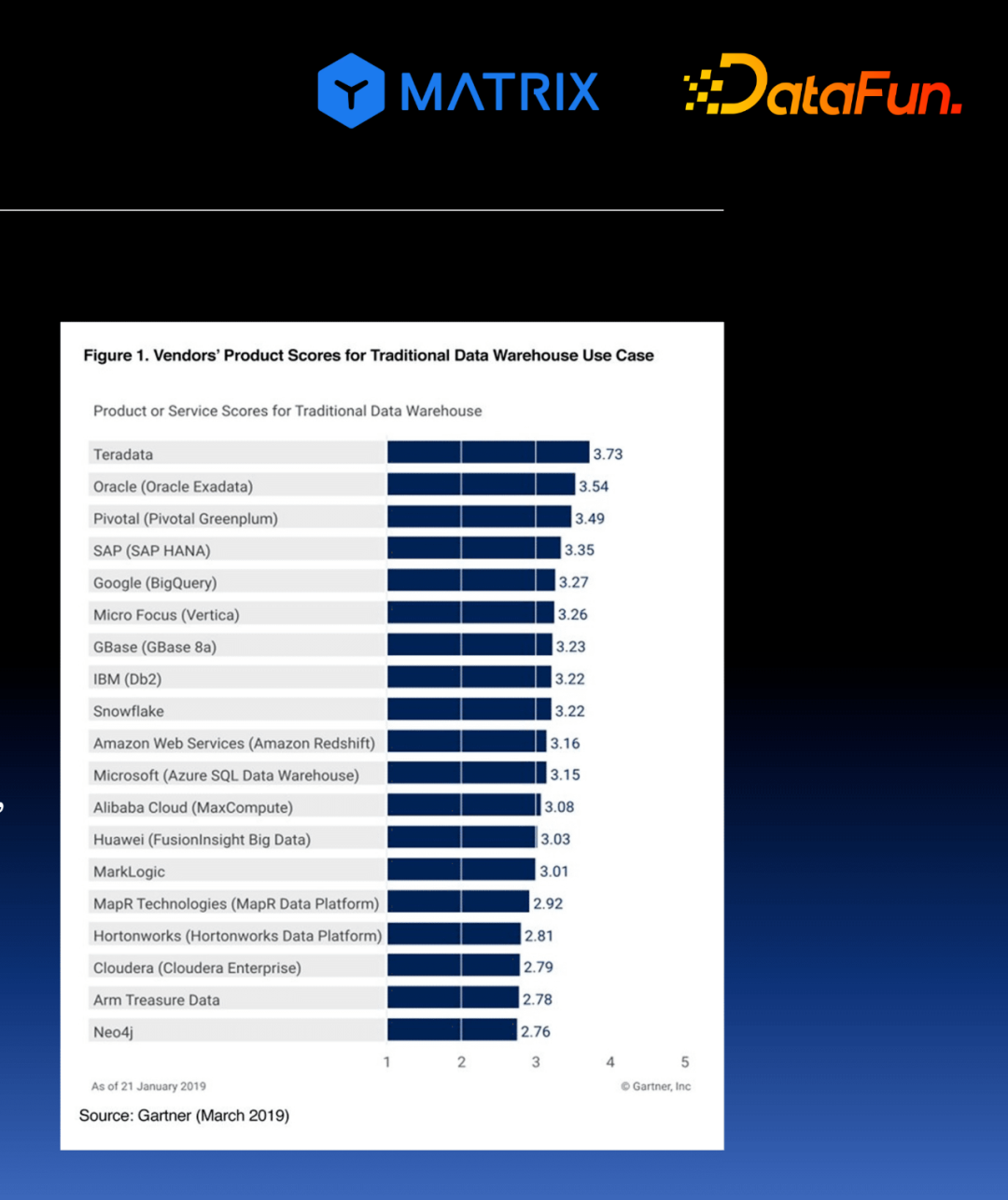
3. MatrixDB 产品认证
权威认证:功能完善,国内唯⼀通过信通院2项认证

数据库的特色是实现时序和分析的超融合,即通过一套数据库系统同时支持时序数据库和分析型数据库这两种场景,因此该产品是全国唯一通过2个认证的产品;另一方面,作为分析型数据库,我们实现了全部27个必选项和24个可选项,成为了国内通过全部51项《分析型数据库认证》的2个产品之一。
4. MatrixDB 产品理念
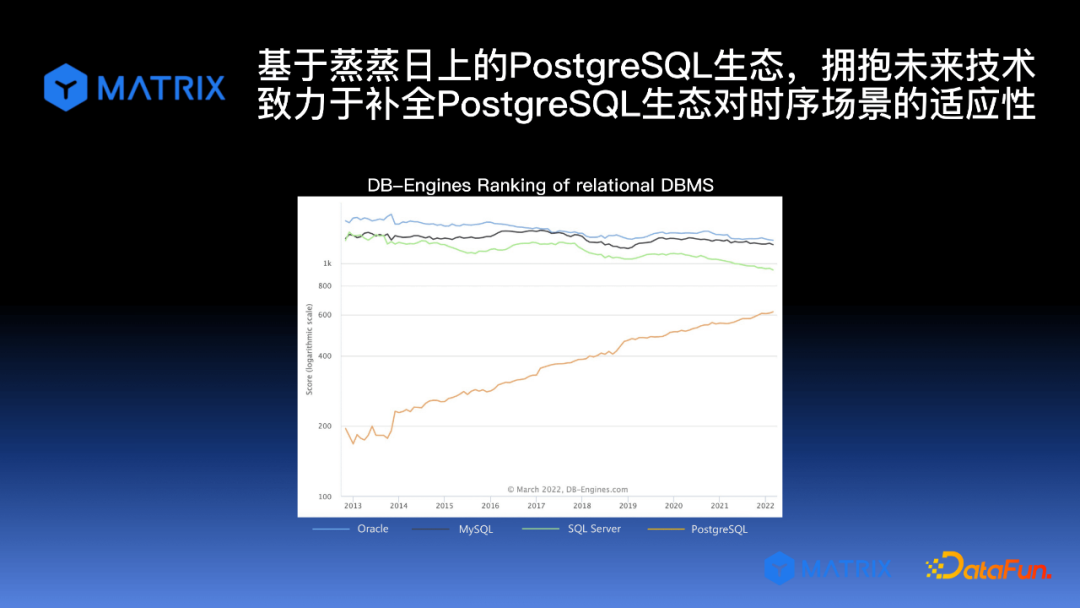
上图展示了几种常见的数据库的近期情况。从图中可以看出,Oracle、MySQL 和 SQL server 这三种传统的关系型数据库自从2003年以来在 DB-Engines 的评分是处于稳中有降的趋势;只有 PostgreSQL 数据库因其良好的生态、友好的商业授权,近十余年持续呈现上升趋势。然而,不管是 PostgreSQL 还是 Greenplum 数据库,对时序数据的支持都不够理想;基于此,MatrixDB 数据库基于 PostgreSQL ⽣态,对时序场景进行了针对性优化,大大提升 PostgreSQL ⽣态对时序场景的适应性。

