前言
数据的加载速度在数据处理和分析领域一直是一个挑战,为应对这一挑战,YMatrix 数据库开发了 mxgate 高速数据加载工具。最近,随着 YMatrix 5.0 的 GA,新版 mxgate 与上一版本(4.8.1)相比,速度提升了一倍;而与 4.8.0 版本相比,加载速度又提升了三倍。
本文将对 mxgate 进行介绍,特别是关注 mxgate 的性能提升和应用场景。如果您需要一个强大的数据加载工具,那么 mxgate 绝对值得您关注。接下来,我们将就其性能提升和应用场景两方面进行详细讨论。
作者:数据库内核研发工程师 张伟晨
一、应用场景
MatrixGate 是 YMatrix 数据库的高速数据加载工具,能帮用户快速地将数据落盘到数据库。其主要特点包括:
-
高速加载:mxgate 能够快速地将数据加载入库,并通过一定的压缩手段突破带宽限制达到极高的吞吐;
-
多种数据格式:mxgate 支持多种数据格式,包括但不限于 text, csv, json, hana 等,用户可以根据需求选择合适的数据格式;
-
多种数据源:mxgate 支持多种数据源,包括但不限于 http, kafka, stdin 等,用户可以根据需求选择合适的数据源。
二、性能提升
从 stdin 加载是 mxgate 的经典场景。虽然 mxgate 的数据加载速度在业内一直遥遥领先,罕逢对手,但是本着孜孜以求,追求极致的工匠精神,我们试图去探测数据加载的极限。经过多次测试,我们定位到数据写入和清洗模块消费能力是足够的,stdin加载场景的瓶颈在数据源模块上,因此在最近的两个版本(5.0与4.8.1)中,我们致力于加快 stdin 模式的入库速度,在以下两个方面做了多阶段优化:
2.1 并行切块
为方便数据清洗,得到一个合适的事务大小,我们会将数据流切块。同时,mxgate 的数据输入为文本模式,这意味着我们 parse 数据流时进行切块的耗时并不能忽视。
以往的版本中,我们同步地读取 stdin 数据流并 parse 出数据块,就像:

Read 和 parse 是互相阻塞的,但是我们服务器一般都具有多个核心,我们可以将 parse 过程独立出来,尽量不阻塞 read。
理想状态下的调度是这样的:
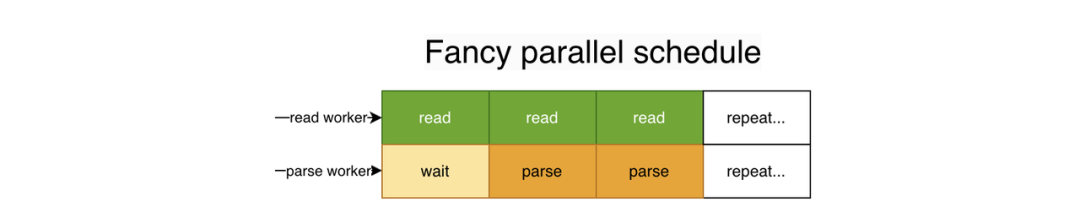
理论上而言,此时他的加载速度将逼近读取文件的速度,但事实是,我们在 parse 完一段内存之前,是无法复用这段内存的。这意味着无论我们 read 的 buffer 有多大,都需要在某个时间点等待这个 buffer 的尾部被 parse 完,那么他的调度需要变成:

我们可以调整切 buffer 以及切块的大小来找到最佳的 read 与 wait parse 的比例,调度的优化告一段落,但是:
为利用更多的服务器资源,我们 parse 完一个数据块后会将数据丢给其他 routine 并进行清洗。这意味着,如果不加处理,这段内存将会被不同的线程读写,所以我们需要把数据从 parse worker 里 copy 出去。
2.2 引用计数
在 parse 阶段中我们发现 copy 数据耗时严重,为减少上图中类举的 wait parse 的耗时,我们引入了一套简单实用的引用计数系统。

如图所示,我们引入了一个内存池,alloc 出一段较大的 buffer 后,把 stdin 的数据读进此 buffer,然后 parse 出多个 block, 并同步地增加对此 buffer 的引用,当此 block 落入数据库时解除引用。引用计数归零时复用这段 buffer,这样就能消除 parse 阶段 copy 数据的耗时,大大提升加载性能。
三、性能测试
3.1 测试环境
MatrixGate 主机一台(数据库 Master 也位于此主机):
Dell PowerEdge R740xd
CPU: 64 * 2.3Ghz
内存: 256G
出口带宽上限: 10000Mb/s (~1.2GB/s)
Segment 主机四台:
硬件规格同上,每个主机部署8个 Primary, 不部署 Mirror。集群共32个 Primary Segment。
进行对比的 mxgate 版本:
v4.8.0(MatrixGate v4.8.0 (git: HEAD 949a38cd))
v4.8.1(MatrixGate v4.8.1 (git: HEAD 6e0ba810))
v5.0.0(MatrixGate v5.0.0 (git: HEAD 53e21dfa))
3.2 准备数据
3.2.1 数据特征
-
数据模拟典型时序场景,由(时间戳)+(设备标识字符串)+(多项混合类型指标)组成。
-
指标字段取值随机性较高。
-
数据文件大小 100G,约 10 亿行;平均每行数据宽度 100Byte 左右。
3.2.2 数据示例
2022-12-10 00:00:00.006|truck_211656|North|Andy|G-2000|v_2.2|5000|300|98|10.65894|94.89509|617|0|311|0|25
2022-12-10 00:00:00.005|truck_887758|North|Andy|G-2000|v_0.5|5000|300|60|26.16685|17.95613|145|0|107|0|25
2022-12-10 00:00:00.007|truck_590862|North|Andy|G-2000|v_0.5|5000|300|39|75.12166|46.19676|800|0|60|0|25
2022-12-10 00:00:00.011|truck_327066|North|Andy|G-2000|v_2.7|5000|300|76|91.66036|65.04679|13|0|828|0|25
2022-12-10 00:00:00.004|truck_892711|North|Andy|G-2000|v_1.7|5000|300|79|70.40157|96.84146|340|0|679|0|25
2022-12-10 00:00:00.031|truck_217686|North|Andy|G-2000|v_0.8|5000|300|53|15.64526|39.67838|346|0|653|0|25
2022-12-10 00:00:00.003|truck_654048|North|Andy|G-2000|v_1.2|5000|300|63|21.35486|41.42145|426|0|964|0|25
2022-12-10 00:00:00.019|truck_284101|North|Andy|G-2000|v_0.4|5000|300|36|33.34589|63.67803|203|0|356|0|25
2022-12-10 00:00:00.017|truck_634570|North|Andy|G-2000|v_1.9|5000|300|63|20.75878|50.45044|132|0|670|0|25
2022-12-10 00:00:00.010|truck_119123|North|Andy|G-2000|v_2.2|5000|300|59|11.14008|43.24966|804|0|529|0|253.2.3 表设计
CREATE TABLE readings(
ts timestamp not null,
name varchar(25),
fleet varchar(25),
driver varchar(25),
model varchar(25),
device_version varchar(25),
load_capacity float4,
fuel_capacity float4,
nominal_fuel_consumption float4,
latitude float4,
longitude float4,
elevation float4,
velocity float4,
heading float4,
grade float4,
fuel_consumption float4
)
using ao_row
with (compresstype='zstd', compresslevel=1)
Distributed by (name);3.3 测试过程
3.3.1 测试 mxgate 4.8.0 加载性能
启动 mxgate 开始加载 /data/readings_
new.csv 中 100G 数据
mxgate \
--source stdin \
--db-master-port 5434\
--time-format raw \
--target public.readings \
--delimiter '|'
